Before understanding what a Service Level Objective (SLO) is and how to do those, we first need to understand what a Service Level Indicator (SLI) is.
According to Google Site Reliability Engineering Book, “SLI is a service level indicator —a carefully defined quantitative measure of some aspect of the level of service that is provided”
So basically, SLI is the measure, what we are measuring. And with the SLI, we can create an SLO.
An SLO is a service level objective: a target value or range of values for a service level that is measured by an SLI. Usually, a structure for SLOs is something like SLI ≤ target, or lower bound ≤ SLI ≤ upper bound. One example of an SLO could be to have an API to have an average latency of fewer than 100 milliseconds.
But how do we know which is the right objective for each of the SLI that we want to monitor? We tech people should not handle this burden alone, choosing targets (SLOs) is not a purely technical activity because of the product and business implications, which should be reflected in both the SLIs and SLOs that are selected.
So, the best solution is to have the engineering team and the product team together to better decide which are the SLIs and SLOs that the product will have because sometime there will be necessary to have some tradeoff between speed of delivery and quality.
This image from Atlassian is a good summary.
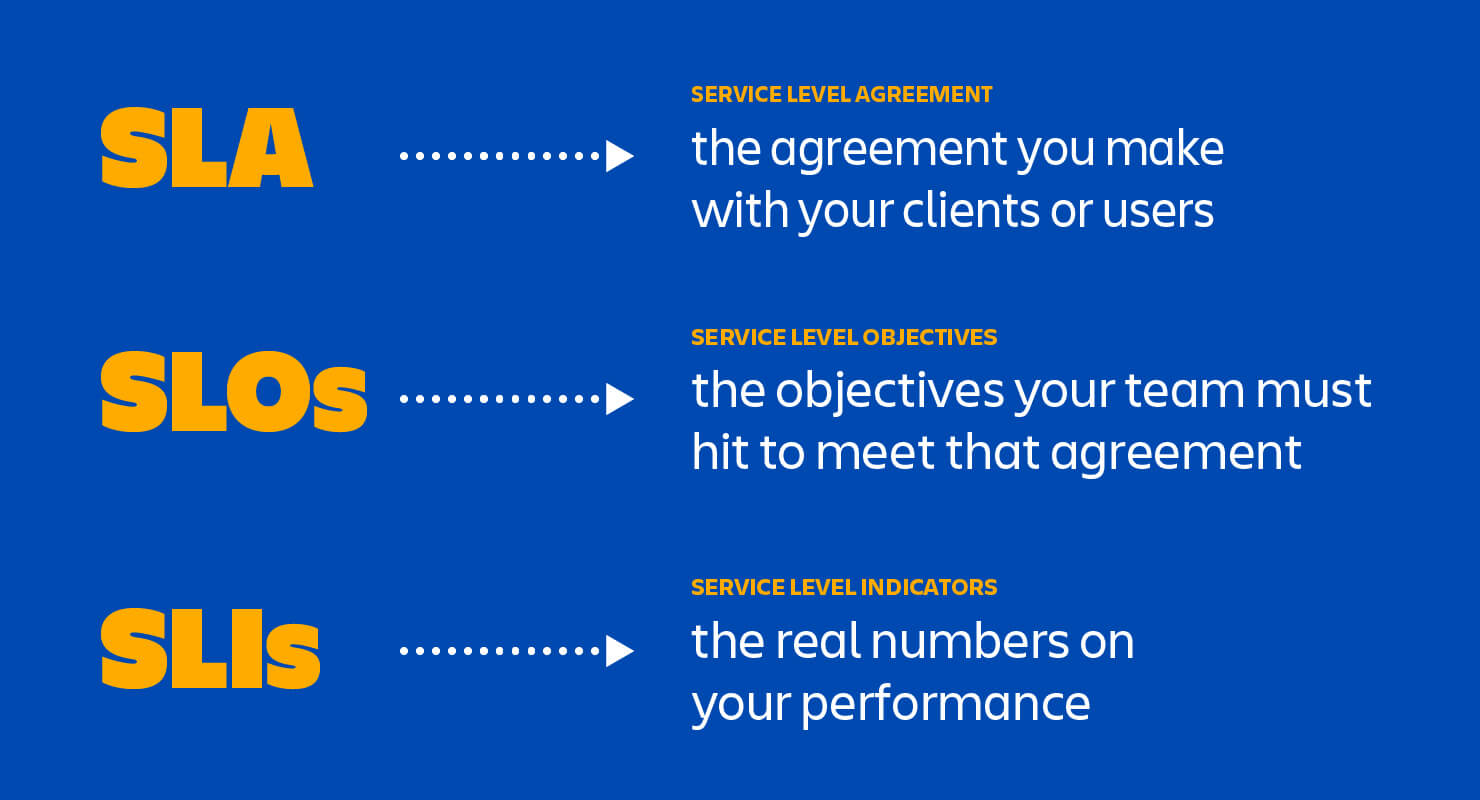
SLA vs SLOs vs SLIs
As the precursor of the SRE, Google’s team learned a few lessons that can help make the discussion between the engineers and product more productive discussion.
Don’t pick a target based on current performance
The natural way is to look at the system in the current state to base the SLOs. but “while understanding the merits and limits of a system is essential, adopting values without reflection may lock you into supporting a system that requires heroic efforts to meet its targets, and that cannot be improved without significant redesign.”
Keep it simple
Do not overcomplicate things, as “complicated aggregations in SLIs can obscure changes to system performance, and are also harder to reason about.”
Avoid absolutes
Nothing is absolute, “while it’s tempting to ask for a system that can scale its load “infinitely” without any latency increase and that is “always” available, this requirement is unrealistic.”
To get close to these absolutes, you probably take a long time to design and build and of course, it will be expensive to operate. This brings a lot of costs and time that your users will never notice or require. The idea is to deliver the best for your users, not more.
Have as few SLOs as possible
Less is more, “choose just enough SLOs to provide good coverage of your system’s attributes. Defend the SLOs you pick: if you can’t ever win a conversation about priorities by quoting a particular SLO, it’s probably not worth having that SLO”
Perfection can wait
Perfect is the enemy of good. It is better to define SLO and you can all refine the definitions and targets over time as you learn about a system’s behavior and your users. “It’s better to start with a loose target that you tighten than to choose an overly strict target that has to be relaxed when you discover it’s unattainable.”
Service Level Objectives (SLOs) are a very good way to prioritize the work of Site Reliability Engineers (SREs) and developers because they measure and reflect what users care about. “A good SLO is a helpful, legitimate forcing function for a development team. But a poorly thought-out SLO can result in wasted work if a team uses heroic efforts to meet an overly aggressive SLO, or a bad product if the SLO is too lax. SLOs are a massive lever: use them wisely.”
Happy coding!
Sources: This post was mainly based on the free book Site Reliability Engineering