We were seeing some weird long queries with more than 10 seconds (sometimes more than 30 seconds) happening on our Postgres database. Looking at logs and traces, we could establish no evident reason for that as their happened randomly and without any specific cause.
What we knew was that was happening in one table only (until it happen in another later a few months later). It was happening only on CREATE and UPDATE (we do not do deletes on this table). The table was reasonably big (more than 2.5 million rows).
Most of the requests were around 35 ms, but for some reason, we had some with long requests that took more than 10 seconds or even 35 seconds.
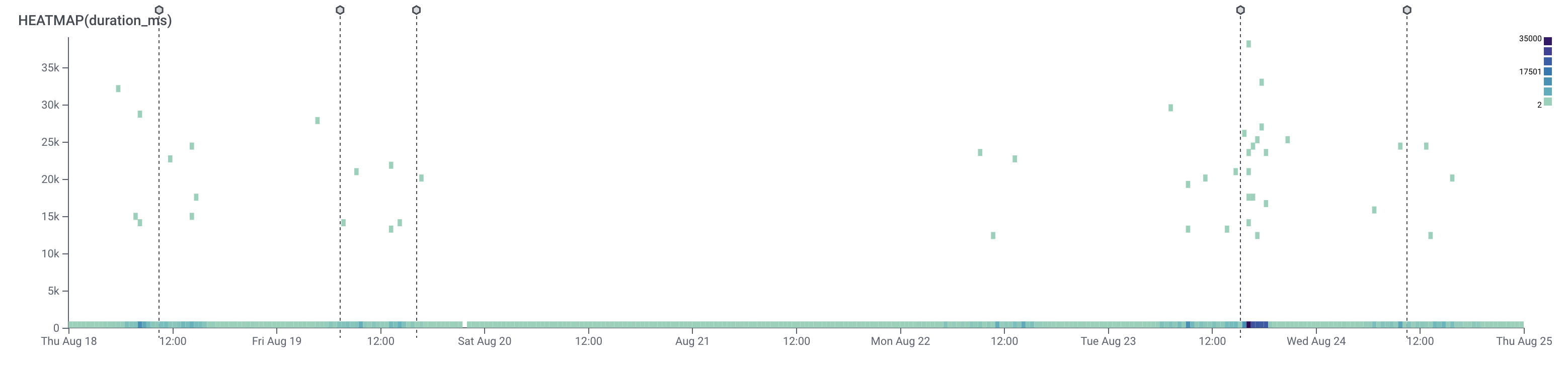
Long queries happening randomly
Looking in Honeycomb, the time spent was during the query itself, all the code for the endpoint and the connection to the database was fine.
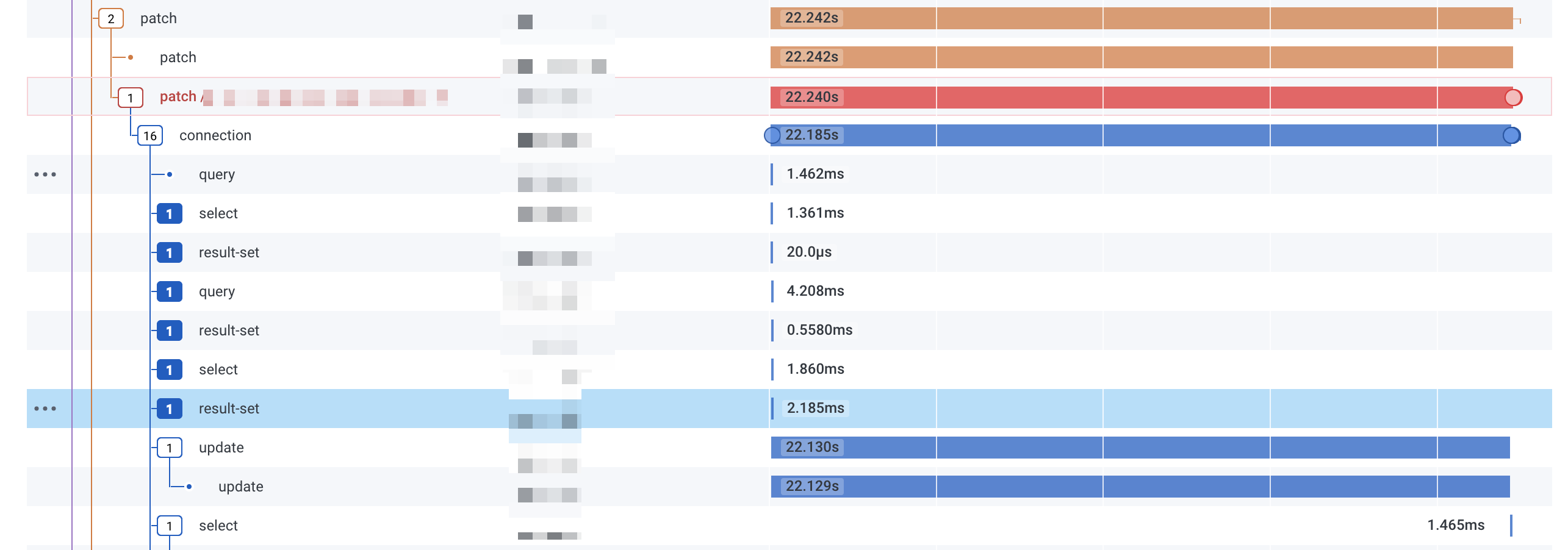
Trace of a random long query
We were thinking that it could be caused by some kind of bad data that we had on the database, but we could not point out the root cause.
After a while of trying things out, no root cause was found.
It was then that we find this question UPDATE on big table in PostgreSQL randomly takes too long on StackExchange.
The reply by jjanes put us on the right track, here is the reply from StackExchange.
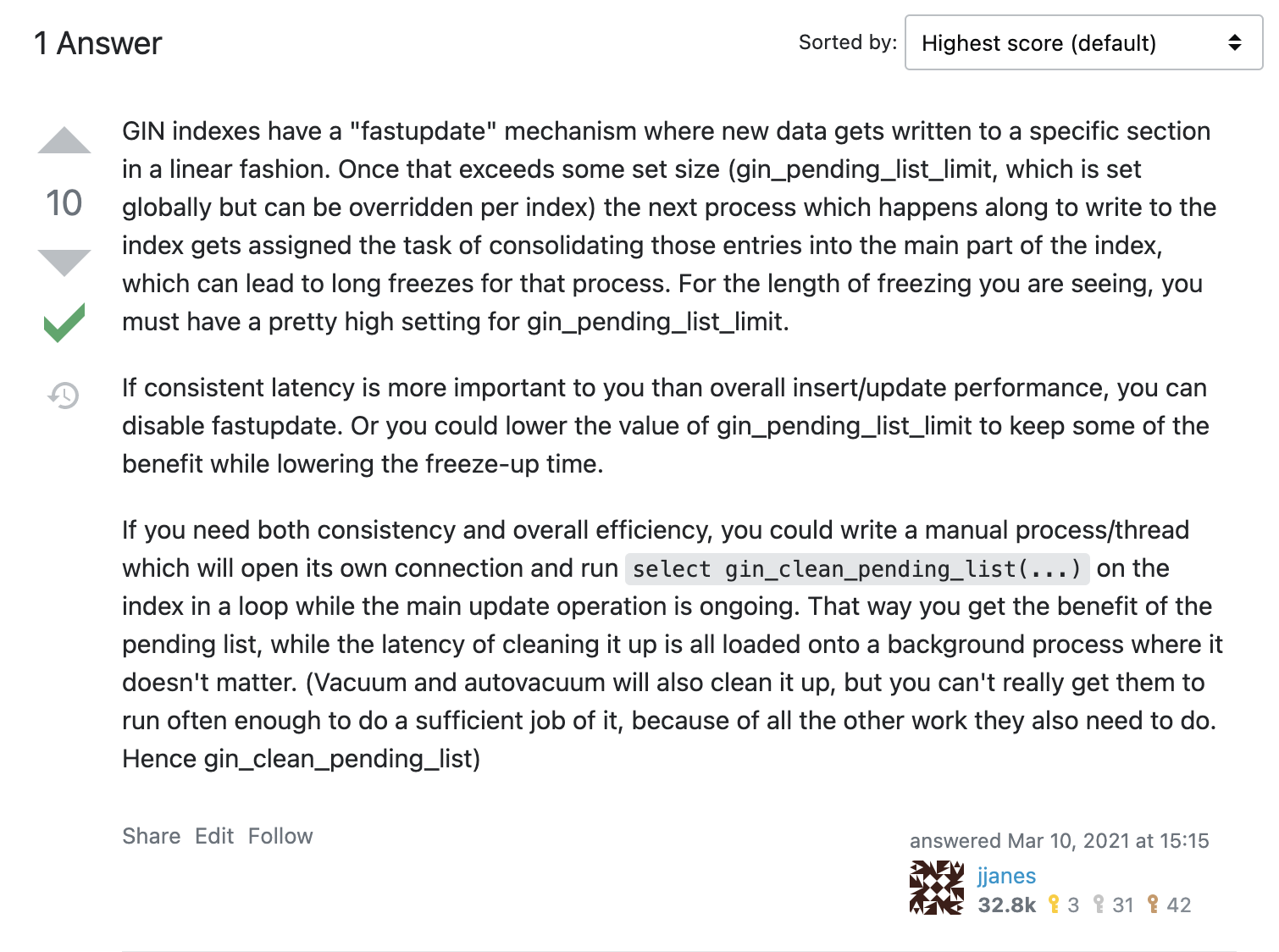
jjanes reply on StackExchange
We checked our table for gin indexes, and yes, we had 5 of them, which gave us a glimpse of hope in finding the root cause of the problem and also fixing it.
How fastupdate in GIN works
As jjanes very well explained in his response in StackExchange, “GIN indexes have a "fastupdate" mechanism where new data gets written to a specific section in a linear fashion. Once that exceeds some set size (gin_pending_list_limit, which is set globally but can be overridden per index) the next process which happens along to write to the index gets assigned the task of consolidating those entries into the main part of the index, which can lead to long freezes for that process.”
The image below from the Postgres documentation illustrates the basic structure of this pending list.
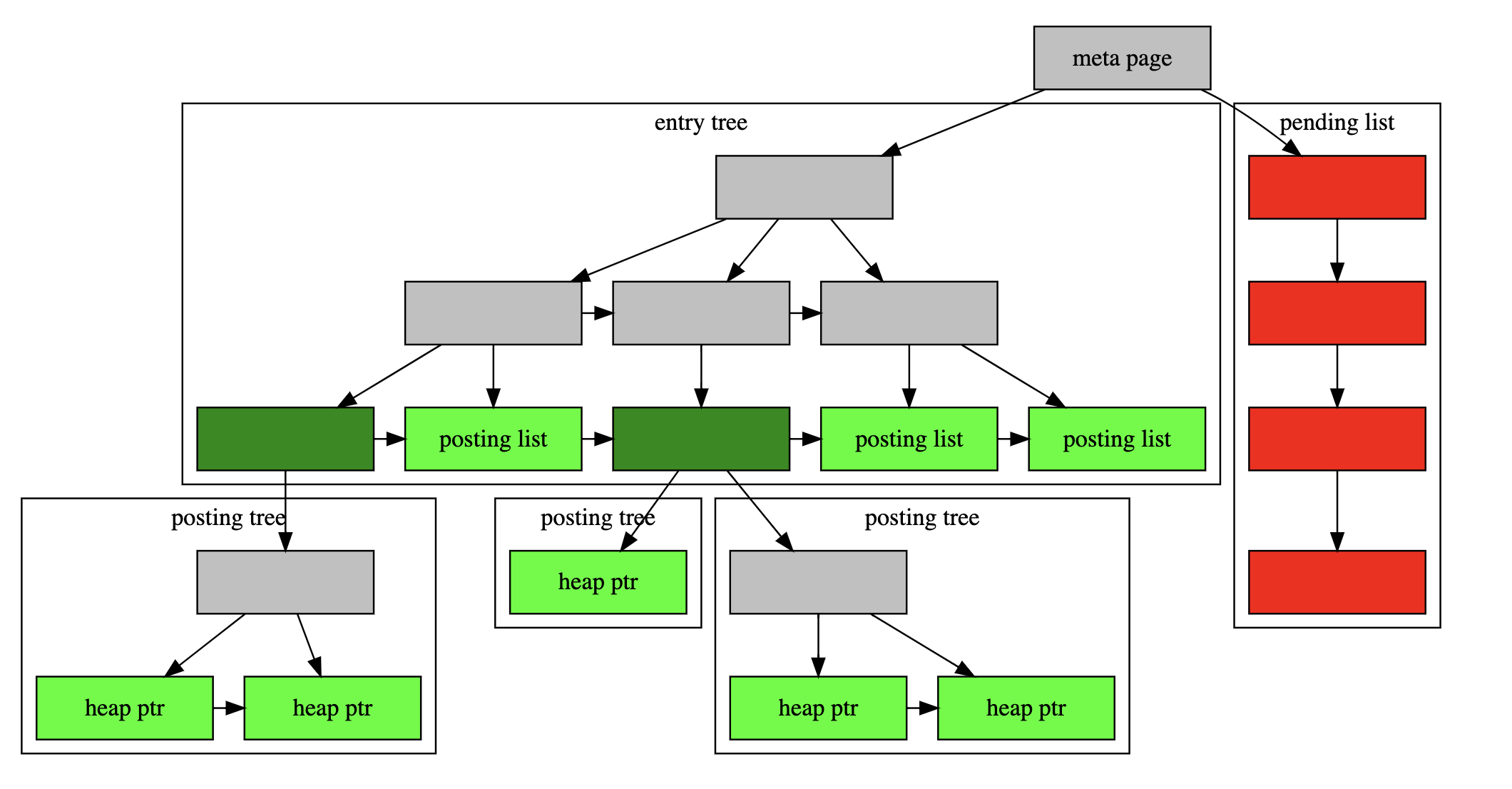
GIN index structure from Postgres documentation
So basically, on new edits (INSERT, UPDATE, DELETE) on the table data, the index changes are written to the pending list (each index has its own) and when it reaches the size (4MB as the default) it has to flush this temporary data it to the main index structure. This flushing to the main index causes that specific query to take a long time.
It can appear random because it will depend on how many GIN indexes you have, how your data is distributed, and other factors.
If this long wait for the consolidation of the index is a problem for your use case, you have a few options to fix this.
How to fix the long queries with GIN index
Dropping unused indexes
The first and more reasonable thing to do is to check if the indexes are really used. It is common to have indexes that are never used or can be replaced by other simpler indexes. So if you do not use it, dropping will fix the problem (for this table/index).
Disable the fastupdate mechanism
If you cannot delete the indexes, one thing that you can do is disable the fastupdate mechanism. Not sure how can you do it globally, but for doing to a specific index you can drop the index and recreate it with fastupdate=off like the following example.
CREATE INDEX IF NOT EXISTS search_table_inx ON your_table USING gin ((your_jsob_field->>'your_mapping') gin_trgm_ops) WITH (fastupdate = off);
This will remove the random long queries but will increase slightly all the inserts/updates for each change in the index, as it will have to persist to the main index (we will not have the pending list anymore)
Just be careful with this approach, because it can take a bit of time to recreate it. If you use flyway migrations and Kubernetes, your pod can be killed for taking a long time during the migration.
Also, CREATE INDEX will lock the table (only writes). for not locking, you can add the CONCURRENTLY keyword like CREATE INDEX CONCURRENTLY. But bear in mind that when using the CONCURRENTLY keyword, the table will not be locked but the table will be scanned twice. So your time to apply the create index will increase.
changing gin_pending_list_limit size
Another option that you have is to decrease the size of the gin_pending_list_limit database parameter. The default value at our DB was 4MB and the minimum you can set is 64KB. Decreasing the pending list size will make the updates to the main index more frequent, making your long queries a bit shorter. How shorter is unknown, you will have to try it out and see if fits your needs.
create a script to clean the pending list on schedule
Another option in theory (I am not sure if will work because I did not try this, so it requires testing) is to increase a lot the pending list and call the select gin_clean_pending_list(...) in a separate script.
What we did to fix it
To solve our problem, we did a bit of most of the options above.
The first thing that to analyze and check if the indexes were really being used. With a bit of refactoring, we were able to remove 3 of the 5 indexes that we had.
For the 2 remaining indexes, we chose to go with disabling the fastupdate for them.
But we also decreased the gin_pending_list_limit to the minimum (64kb) to avoid this happening for the other GIN indexes that we have our services. We did not have to analyze all the database indexes so we decided that reducing the gin_pending_list_limit was a good solution.
I hope that this helps you in developing better experiences for your users avoiding GIN index long queries.
Happy coding!
A big thanks to jjanes as his answer pointed to the right direction and helped us solve the problem.