When we developers start a project from scratch, we usually use the default values for most of the configurations and that is very useful as it makes everything very easy to start. Also, the default values work for the majority of the cases. This is also true for the prefetch count in RabbitMQ consumers.
When using Spring AMQP version 2.x, the default for prefetch count is 250, and for most cases that works great. It works so great to the point that many developers don’t even need to know about the existence of this parameter or its default value.
I recently faced a situation where the value of the prefetch count was mattering a lot and the default value didn’t work anymore.
Before starting to describe the situation, let’s see what the docs say about the prefetch count.
The Spring AMQP definition of prefetchCount is
“The number of unacknowledged messages that can be outstanding at each consumer. The higher this value is, the faster the messages can be delivered, but the higher the risk of non-sequential processing. Ignored if the
acknowledgeModeisNONE. This is increased, if necessary, to match thebatchSizeormessagePerAck. Defaults to 250 since 2.0. You can set it to 1 to revert to the previous behavior.”
The idea to increase the prefetch is to reduce the communication overhead as it fetches many more messages at once. The greater the prefetch count, the lower the communication overhead.
So, does that means that the higher the prefetch the better? Not necessarily, let’s take an example of an actual situation that was happening.
real case scenario
I was facing a situation where the messages were not being consumed at a desirable rate. We had a process that added around a thousand messages to the queue every hour (around 7 times a day) and we wanted all of them consumed in around 40 minutes, so when the new process added the messages to the queue again, the queue would be empty and the consumers would start consuming and processing that new messages.
What was happening was that the messages started to accumulate in the queue as the consumption rate was not able to handle everything before new ones were added.
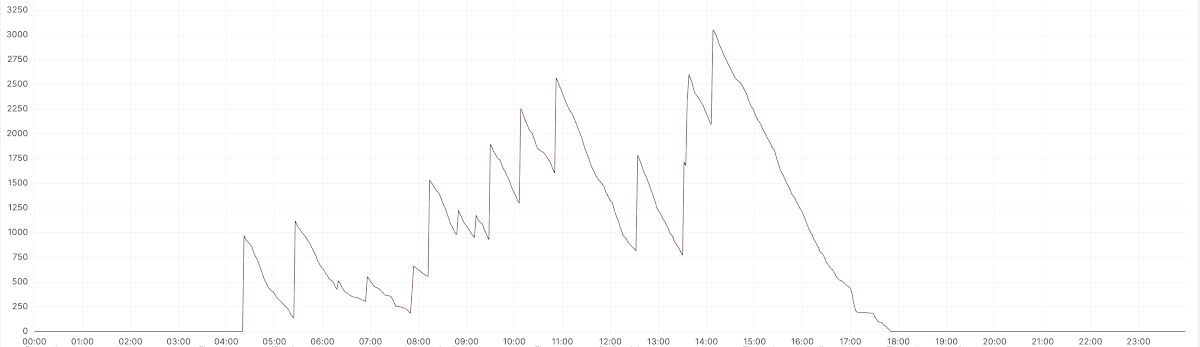
Total messages (active + unacknowledged) before
We had the minimum concurrent consumer values as 3 and the maximum concurrent consumers set as 6.
The first thought was to increase the number of concurrent consumers in order to be able to process more events in parallel, so we did it. We increased the number of maximum consumers to 12 but we didn’t see much improvement.
Looking at the number of consumers being used, we noticed that the consumer number rarely went above 6, even though we had around 1.5k messages in the queue.
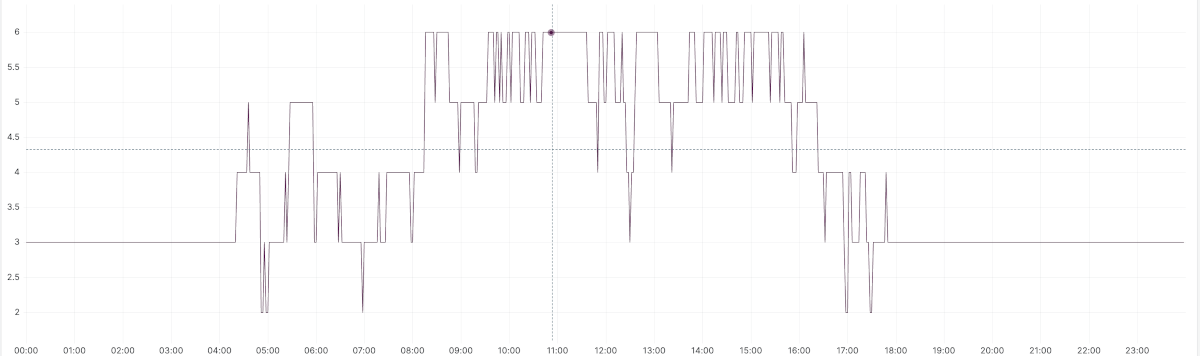
Used concurrent consumers before
It was when we looked at the number of unacknowledged messages that the light stroke for us. As we never changed the number of the prefetch count, every consumer was prefetching 250 messages. So if we have 1.5k in the queue, we would only be using 6 consumers (1500/250 = 6).
If we wanted to improve throughput, what we need to do was to also decrease the number of prefetch count, so more consumers could be started and would be able to work in parallel.
We tried that, we decreased the prefetch count from 250 to 5 (in many steps) so if we had more than 30 messages ready in the queue, the AMQP could spin out more consumers to handle it.
After a few interactions, we set the prefetch as 5 and the number of max concurrent consumers to 30. We set the minimum number of active consumers as 15. We also made also decreased the consecutiveActiveTrigger from 10 to 2 so the consumers would scale up faster. The images below show the result.
This shows the total number of messages in the queue (active + unacknowledge)
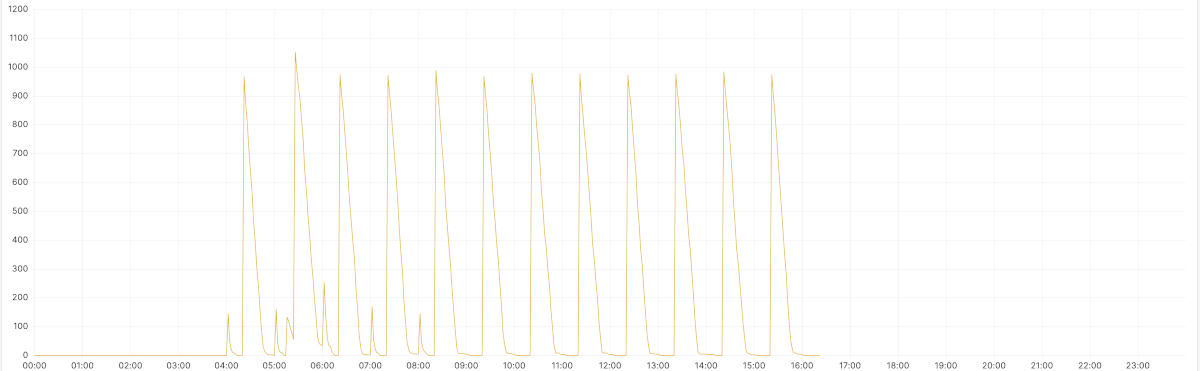
Total messages (active + unacknowledged) after
This shows the current number of consumers.
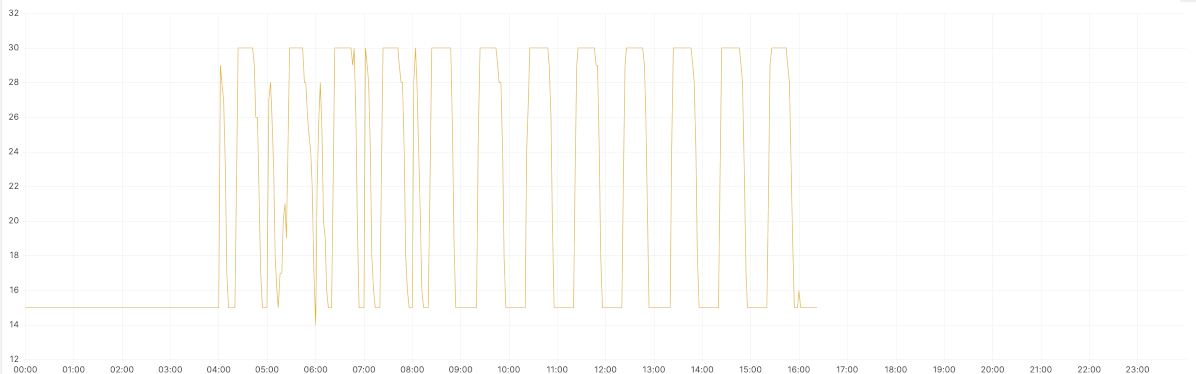
Used concurrent consumers after
Why did we need to adjust the prefetch count? Turns out the processing of the messages for us is slow, so it can take up to a few minutes for the message to be consumed and processed. As the bottleneck was the processing, in order for us to process faster we need to prefetch less so more consumers could be spun to handle messages in parallel.
The docs have a very clear warning about the prefetch count.
“There are scenarios where the prefetch value should be low — for example, with large messages, especially if the processing is slow (messages could add up to a large amount of memory in the client process), and if strict message ordering is necessary (the prefetch value should be set back to 1 in this case). Also, with low-volume messaging and multiple consumers (including concurrency within a single listener container instance), you may wish to reduce the prefetch to get a more even distribution of messages across consumers.”
Our user case fell in the “especially if the processing is slow” case.
Happy coding!